Oric Lawson
Sexta à tarde, o projeto OpenZFS peito Versão 2.1.0 do nosso sistema de arquivos favorito perene “É complicado, mas vale a pena”. A nova versão é compatível com FreeBSD 12.2-RELEASE e posterior, e Linux kernels 3.10-5.13. Esta versão apresenta várias melhorias gerais de desempenho, bem como alguns recursos completamente novos – principalmente voltados para organizações e outros casos de uso muito avançados.
Hoje, vamos nos concentrar no maior recurso que o OpenZFS 2.1.0 adiciona – a topologia dRAID vdev. O dRAID está em desenvolvimento ativo desde pelo menos 2015 e atingiu o status beta quando integrado Em OpenZFS master em novembro de 2020. Desde então, ele foi fortemente testado em várias lojas de desenvolvimento OpenZFS – o que significa que a versão de hoje é “fresca” na condição de produção, não “nova” como não testada.
Visão geral do RAID distribuído (dRAID)
Se você já pensou que a topologia ZFS era um arquivo composto Assunto, prepare-se para explodir sua mente. RAID distribuído (dRAID) é uma topologia vdev inteiramente nova que encontramos pela primeira vez em uma apresentação no OpenZFS Dev Summit 2016.
Ao criar um dRAID vdev, o administrador especifica o número de setores de dados, paridade e pontos de acesso para cada faixa. Esses números são independentes do número de discos físicos em vdev. Podemos ver isso na prática no exemplo a seguir, que foi retirado dos conceitos básicos do dRAID documentação:
root@box:~# zpool create mypool draid2:4d:1s:11c wwn-0 wwn-1 wwn-2 ... wwn-A
root@box:~# zpool status mypool
pool: mypool
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
draid2:4d:11c:1s-0 ONLINE 0 0 0
wwn-0 ONLINE 0 0 0
wwn-1 ONLINE 0 0 0
wwn-2 ONLINE 0 0 0
wwn-3 ONLINE 0 0 0
wwn-4 ONLINE 0 0 0
wwn-5 ONLINE 0 0 0
wwn-6 ONLINE 0 0 0
wwn-7 ONLINE 0 0 0
wwn-8 ONLINE 0 0 0
wwn-9 ONLINE 0 0 0
wwn-A ONLINE 0 0 0
spares
draid2-0-0 AVAILTopologia Dredd
No exemplo acima, temos onze discos: wwn-0 Através wwn-A. Criamos um draID vdev com 2 dispositivos de paridade, 4 dispositivos de dados e 1 dispositivo de backup por fita – em linguagem condensada, draid2:4:1.
Embora tenhamos onze discos no total em um arquivo draid2:4:1, apenas seis são usados em cada barra de dados – e um em cada barra físico – físico – fita. Em um mundo de aspiradores de pó perfeitos, superfícies sem atrito e galinhas esféricas, o layout do disco draid2:4:1 Isso parecerá assim:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | uma |
| s | s | s | Dr | Dr | Dr | Dr | s | s | Dr | Dr |
| Dr | s | Dr | s | s | Dr | Dr | Dr | Dr | s | s |
| Dr | Dr | s | Dr | Dr | s | s | Dr | Dr | Dr | Dr |
| s | s | Dr | s | Dr | Dr | Dr | s | s | Dr | Dr |
| Dr | Dr | . | . | s | . | . | . | . | . | . |
| . | . | . | . | . | s | . | . | . | . | . |
| . | . | . | . | . | . | s | . | . | . | . |
| . | . | . | . | . | . | . | s | . | . | . |
| . | . | . | . | . | . | . | . | s | . | . |
| . | . | . | . | . | . | . | . | . | s | . |
| . | . | . | . | . | . | . | . | . | . | s |
Efetivamente, o Dredd leva o conceito de RAID de “paridade diagonal” um passo adiante. O RAID5 não foi a primeira topologia de paridade RAID – foi o RAID3, no qual a paridade estava localizada em um disco rígido, ao invés de distribuída por todo o array.
O RAID5 eliminou a unidade de paridade rígida e, em vez disso, distribuiu a paridade em todos os discos de array – fornecendo gravações aleatórias muito mais rápidas do que o RAID3 conceitualmente mais simples, porque não impedia todas as gravações em um disco de paridade rígido.
O dRAID pega esse conceito – distribuir paridade em todos os discos, em vez de agregar tudo em um ou dois discos rígidos – e estende-o para spares. Se o disco falhar em dRAID vdev, os setores de paridade e os dados que residem no disco morto são copiados para um ou mais setores sobressalentes reservados para cada fita afetada.
Vamos pegar o gráfico simplificado acima e ver o que acontece se tirarmos um disco da matriz. A falha inicial deixa lacunas na maioria dos conjuntos de dados (neste diagrama simplificado, linhas):
| 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | uma | |
| s | s | s | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | s | Dr | s | Dr | Dr | Dr | Dr | s | s | |
| Dr | Dr | s | Dr | s | s | Dr | Dr | Dr | Dr | |
| s | s | Dr | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | Dr | . | s | . | . | . | . | . | . |
Mas quando usamos resilver, fazemos isso na capacidade sobressalente reservada anteriormente:
| 0 | 1 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | uma | |
| Dr | s | s | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | s | Dr | s | Dr | Dr | Dr | Dr | s | s | |
| Dr | Dr | Dr | Dr | s | s | Dr | Dr | Dr | Dr | |
| s | s | Dr | Dr | Dr | Dr | s | s | Dr | Dr | |
| Dr | Dr | . | s | . | . | . | . | . | . |
Observe que esses gráficos são simplificado. O quadro completo inclui grupos, slides e aulas que não tentaremos abordar aqui. O layout lógico também é embaralhado aleatoriamente para distribuir as coisas uniformemente entre as unidades com base no deslocamento. Os interessados nos menores detalhes são incentivados a dar uma olhada nesses detalhes Suspensão No commit do código original.
Também é importante notar que o dRAID requer larguras de faixas estáticas – não as larguras dinâmicas que os vdevs RAIDz1 e RAIDz2 tradicionais suportam. Se estivermos usando discos 4kn, o arquivo. draid2:4:1 Um vdev como o mostrado acima exigiria 24 KB no disco por bloco de metadados, enquanto um vdev RAIDz2 de seis larguras convencional só precisa de 12 KB. Essa discrepância piora quanto mais altos são os valores d+p Obter draid2:8:1 Isso exigiria incríveis 40 KB para o mesmo bloco de metadados!
Por este motivo, o special O alocador vdev é muito útil em pools com dRAID vdevs – quando há um pool com ele draid2:8:1 e três de largura special Ele precisa armazenar um bloco de metadados de 4 KB, faz isso em apenas 12 KB em um arquivo special, em vez de 40 KB em um arquivo draid2:8:1.
Desempenho DREAD, Tolerância a Falhas e Retorno
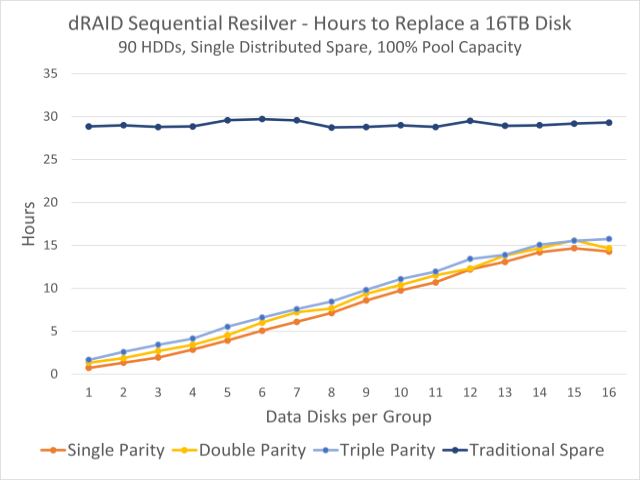
Este gráfico mostra os tempos de reemergência observados para um pool de 90 discos. A linha azul escura na parte superior é o tempo de refiltro em um disco rígido fixo; As linhas coloridas abaixo indicam os tempos de liquidação da capacidade de reserva distribuída.
Na maior parte, dRAID vdev funcionará de forma semelhante a um conjunto equivalente de vdevs tradicionais – por exemplo, draid1:2:0 Em nove discos, ele funcionará de forma quase equivalente a um conjunto de três vdevs RAIDz1 de largura 3. A tolerância a falhas também é semelhante – você tem a garantia de sobreviver a uma única falha com p=1, assim como você está com RAIDz1 vdevs.
Observe que dissemos que a tolerância a falhas é semelhante, não eram idênticos. Um conjunto tradicional de três vdevs RAIDz1 de largura 3 só tem garantia de sobreviver a uma única falha de disco, mas provavelmente durará um segundo – desde que o segundo disco que falhe não faça parte do mesmo vdev que o primeiro, está tudo bem .
em nove discos draid1:2, uma segunda falha de disco quase certamente mataria o vdev (e o pacote com ele), E se Essa falha ocorre antes de você sobreviver. Uma vez que não há conjuntos fixos de fontes individuais, é muito provável que uma segunda falha de disco desative setores adicionais em fontes já degradadas, independentemente do Que O segundo disco falhou.
Essa falta de tolerância a falhas é um pouco compensada por tempos de resilver exponencialmente mais rápidos. No gráfico no topo desta seção, podemos ver que em um lote de noventa discos de 16 TB, você está balançando uma máquina convencional estacionária. spare Leva cerca de trinta horas, não importa como configuramos o dRAID vdev – mas reaparecer na redundância distribuída pode levar menos de uma hora.
Isso se deve em grande parte à reformatação em uma partição distribuída que divide a carga de gravação entre todos os discos restantes. Quando você usa no estilo tradicional spare, o próprio disco de backup é um gargalo – as leituras vêm de todos os discos em vdev, mas todas as gravações devem ser concluídas com o backup. Mas quando a capacidade redundante distribuída é redesenhada, ambos são lidos E a As cargas de trabalho de gravação são divididas entre todos os discos restantes.
Um resilver distribuído também pode ser um resilver serial, em vez de um processador resilver – o que significa que o ZFS pode simplesmente copiar todos os setores afetados, sem se preocupar com o quê blocks Esses setores pertencem a. Por outro lado, os resilvers de cura devem varrer toda a árvore de blocos – o que resulta em uma carga de trabalho de leitura aleatória, em vez de uma carga de trabalho de leitura sequencial.
Quando a substituição física do disco com falha é adicionada à montagem, esta revenda vontade É escalar, não sequencial – e prejudica o desempenho de gravação de um disco sobressalente individual, em vez de todo o vdev. Mas o tempo para concluir esse processo é muito menos importante, porque o vdev nem mesmo está em um estado de degradação.
Conclusões
As versões RAID vdevs distribuídas são frequentemente destinadas a grandes servidores de armazenamento – OpenZFS draid Projeto e teste giraram em grande parte em torno de sistemas de 90 discos. Em uma escala menor, arquivos vdevs tradicionais e spares Continua tão útil quanto antes.
Advertimos especialmente os iniciantes no armazenamento a serem cuidadosos com eles draid—É um layout significativamente mais complexo do que agrupar com vdevs tradicionais. A flexibilidade rápida é ótima – mas draid Ele atinge o sucesso em ambos os níveis de estresse e certos cenários de desempenho devido às suas linhas de comprimento necessariamente fixo.
Enquanto os discos tradicionais continuam a aumentar de tamanho sem aumentar significativamente o desempenho, draid Sua rápida reconfiguração pode se tornar desejável mesmo em sistemas menores – mas levará algum tempo para descobrir exatamente onde o ponto ideal começa. Nesse ínterim, lembre-se de que o RAID não é um backup – isso inclui draid!